This guide explains how to choose which fields are displayed in the component.
The fields shown on the grid or chart are called a data slice (or simply a slice). In code, the slice is defined using the SliceObject.
To see different examples of the slice configuration, visit our Examples page.
To specify which fields appear in the component, add them to the respective report.slice array: slice.rows, slice.columns, slice.measures, or slice.reportFilters.
Check out an example of a configured slice:
slice: {
rows: [
{
uniqueName: "Category"
}
],
columns: [
{
uniqueName: "Country"
},
{
uniqueName: "[Measures]"
}
],
measures: [
{
uniqueName: "Price"
}
],
reportFilters: [
{
uniqueName: "Color",
filter: {
members: [
"color.[yellow]",
"color.[white]"
]
}
}
]
}Note Measures are displayed in the columns area by default. Learn how to manage the measures position.
You can change the slice using the following API calls:
let slice = {
rows: [
{
uniqueName: "Country"
}
],
columns: [
{
uniqueName: "Color"
}
],
measures: [
{
uniqueName: "Price"
}
]
};
pivot.runQuery(slice);let report = {
slice: {
// Your slice configs
},
// Other configs
}
pivot.setReport(report);
Open the Field List and drag fields to the necessary areas: Rows, Columns, Values, or Report filters. Learn how to use the Field List:
To reorder the fields on the grid, drag them between columns, rows, and report filters. It is also possible to drag fields out of the grid.
By default, measures are displayed in the Columns area after other fields. You can override this behaviour by explicitly setting where the measures should appear.
To place measures in rows, specify the [Measures] array in the slice.rows:
slice: {
rows: [
{
uniqueName: "Category"
},
{
uniqueName: "[Measures]"
}
],
columns: [
{
uniqueName: "Country"
}
],
measures: [
{
uniqueName: "Price",
aggregation: "sum"
},
{
uniqueName: "Discount",
aggregation: "min"
}
]
}The grid view changes depending on whether the measures are placed before, in between, or after the other fields. Check out the example:
slice: {
rows: [
{
uniqueName: "Category"
}
],
columns: [
{
uniqueName: "Country"
},
{
uniqueName: "[Measures]"
},
{
uniqueName: "Color"
}
],
measures: [
{
uniqueName: "Price",
aggregation: "sum"
},
{
uniqueName: "Quantity",
aggregation: "sum"
}
]
}You can choose which fields to show in the flat table using one of the following approaches:
All fields that are defined in the slice.rows, slice.columns, slice.reportFilters, and slice.measures arrays will be displayed in the flat view in the order they are listed in the arrays. See how to change the order of the fields.
We recommend specifying fields to show in the flat form using only slice.columns:
slice: {
columns: [
{
uniqueName: "Country"
},
{
uniqueName: "Category"
},
// Other fields
]
}
You can change the slice for the flat view using the following API calls:
let slice = {
columns: [
{ uniqueName: "Country" },
{ uniqueName: "Color" },
{ uniqueName: "Price" }
]
};
pivot.runQuery(slice);let report = {
slice: {
columns: [
{
uniqueName: "Country"
},
{
uniqueName: "Category"
},
// Other fields
]
},
// Other configs
}
pivot.setReport(report);
Use the Field List to choose fields to show.
To specify the field order in the flat table, use the slice.flatOrder property:
slice: {
flatOrder: [
"Month",
"Category",
"Customer",
"Payment Method",
"Revenue"
],
rows: [
{
uniqueName: "Category"
},
{
uniqueName: "Customer"
},
{
uniqueName: "Payment Method"
}
],
columns: [
{
uniqueName: "Month"
},
{
uniqueName: "[Measures]"
}
],
measures: [
{
uniqueName: "Revenue"
}
]
}As a result, fields on the grid will be displayed in the same order as in the slice.flatOrder.
Specify the slice.flatOrder property within one of the following API calls:
To reorder the fields on the grid, drag them between columns. You can also drag fields out of the grid:
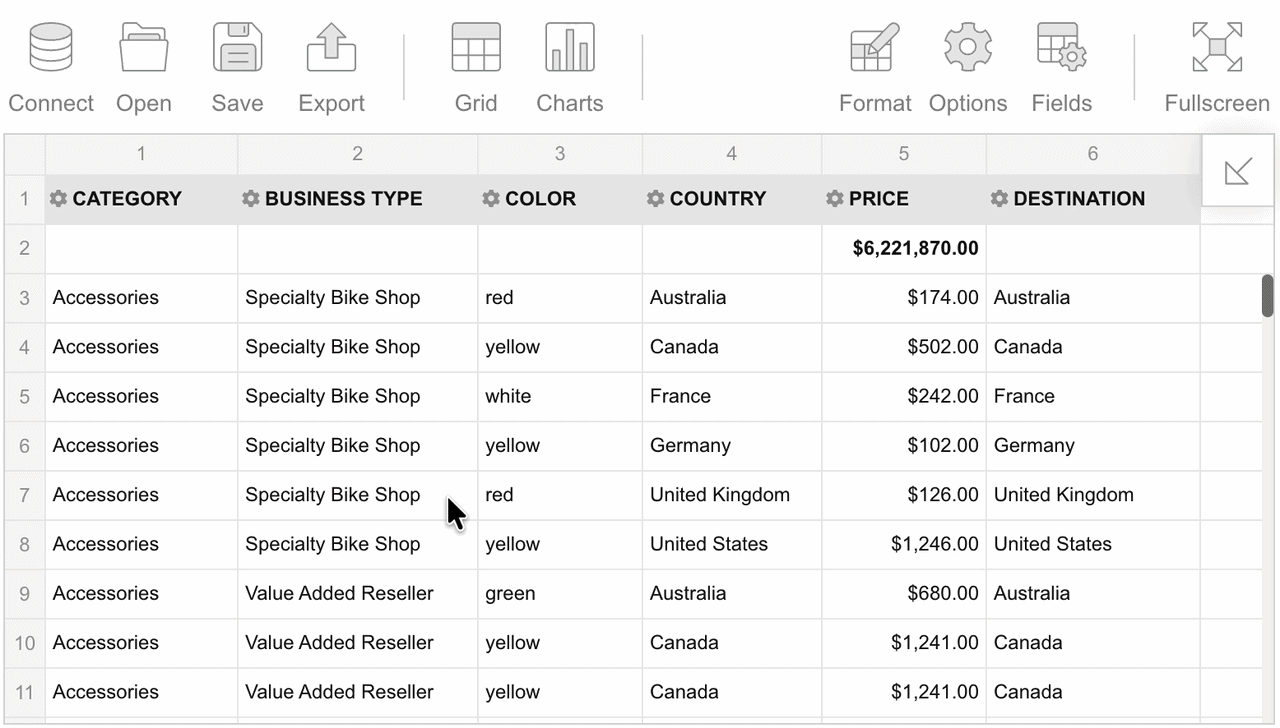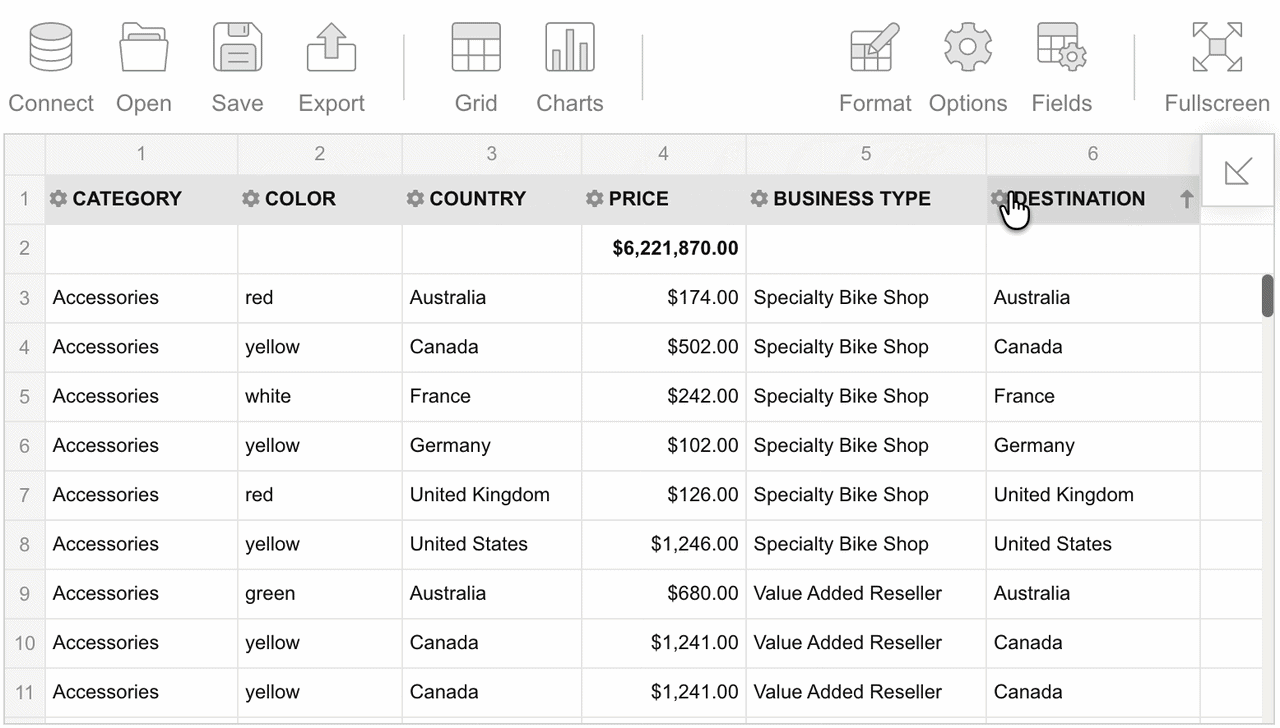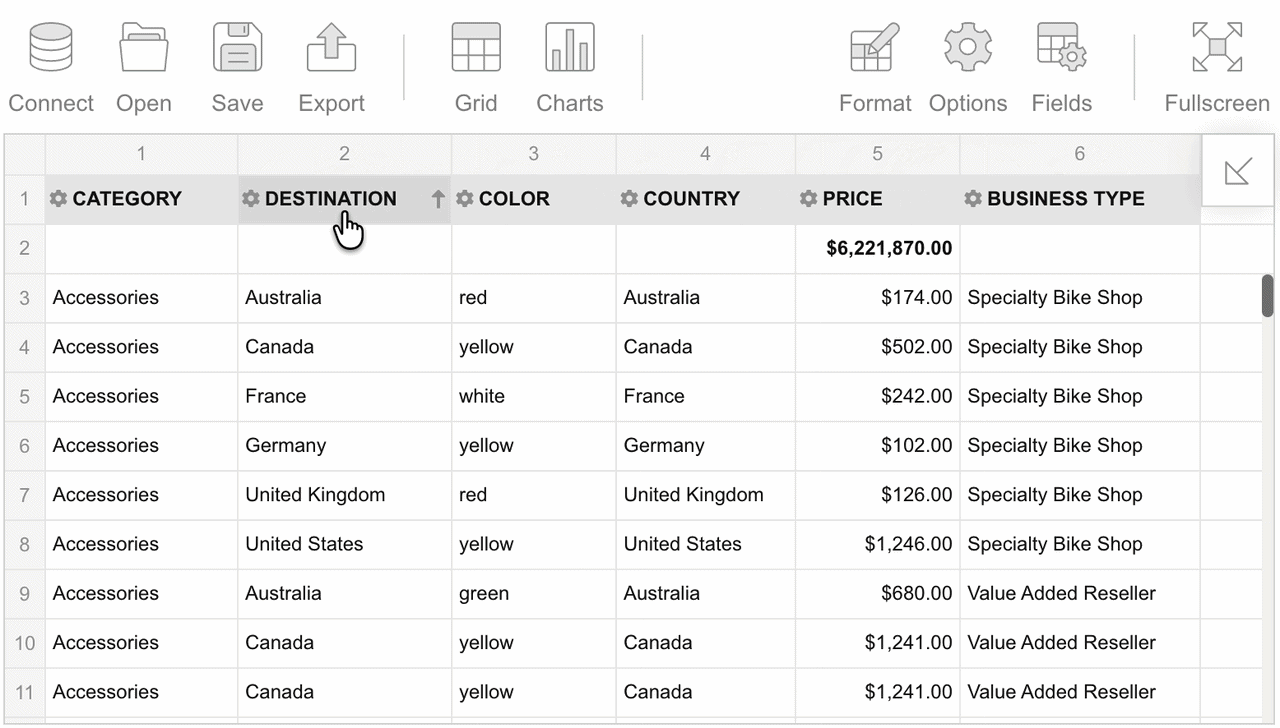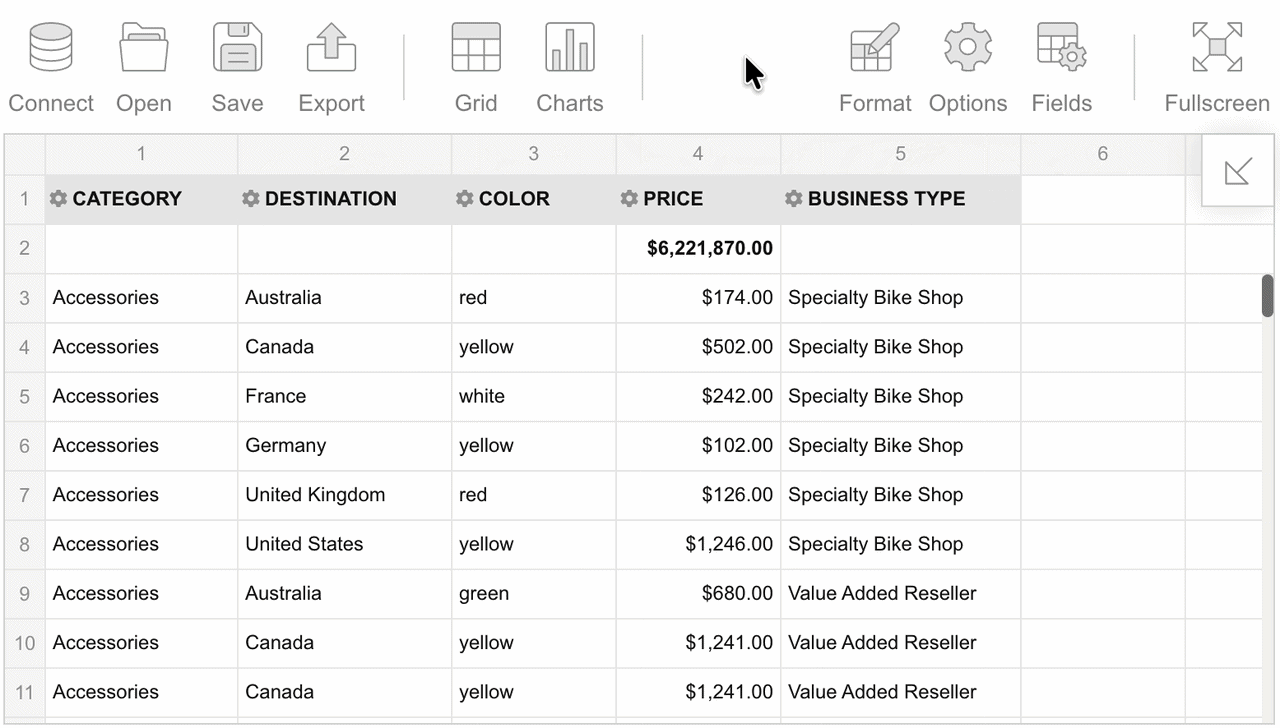
It is also possible to reorder fields in the Field List.
If a slice is not defined, Flexmonster will set a default slice for the report:
The default slice is selected automatically only for JSON and CSV data sources. You can turn off this feature by setting the options.showDefaultSlice to false.
Check out the following JSON data:
[
{
"Price": 125,
"Category": "Accessories",
"Country": "Canada",
"Quantity": 100
},
{
"Price": 233,
"Category": "Bikes",
"Country": "France",
"Quantity": 184
}
]
"Category" is the first string field, so it goes to rows. "Price" is the first measure, so it goes to measures. The default slice for this dataset looks as follows:
slice: {
rows: [
{
uniqueName: "Category"
}
],
columns: [
{
uniqueName: "[Measures]"
}
],
measures: [
{
uniqueName: "Price"
}
]
}By default, the drill-through view displays all fields defined in the slice.rows, slice.columns, slice.measures, and slice.reportFilters arrays. See how to preset the slice for the drill-through view in the report or configure it via the UI:
To configure which fields will be present in the drill-through view, specify the fields in the slice.drillThrough array:
slice: {
drillThrough: [
"Country",
"Category",
"Color",
"Price"
],
// Other slice configurations
}
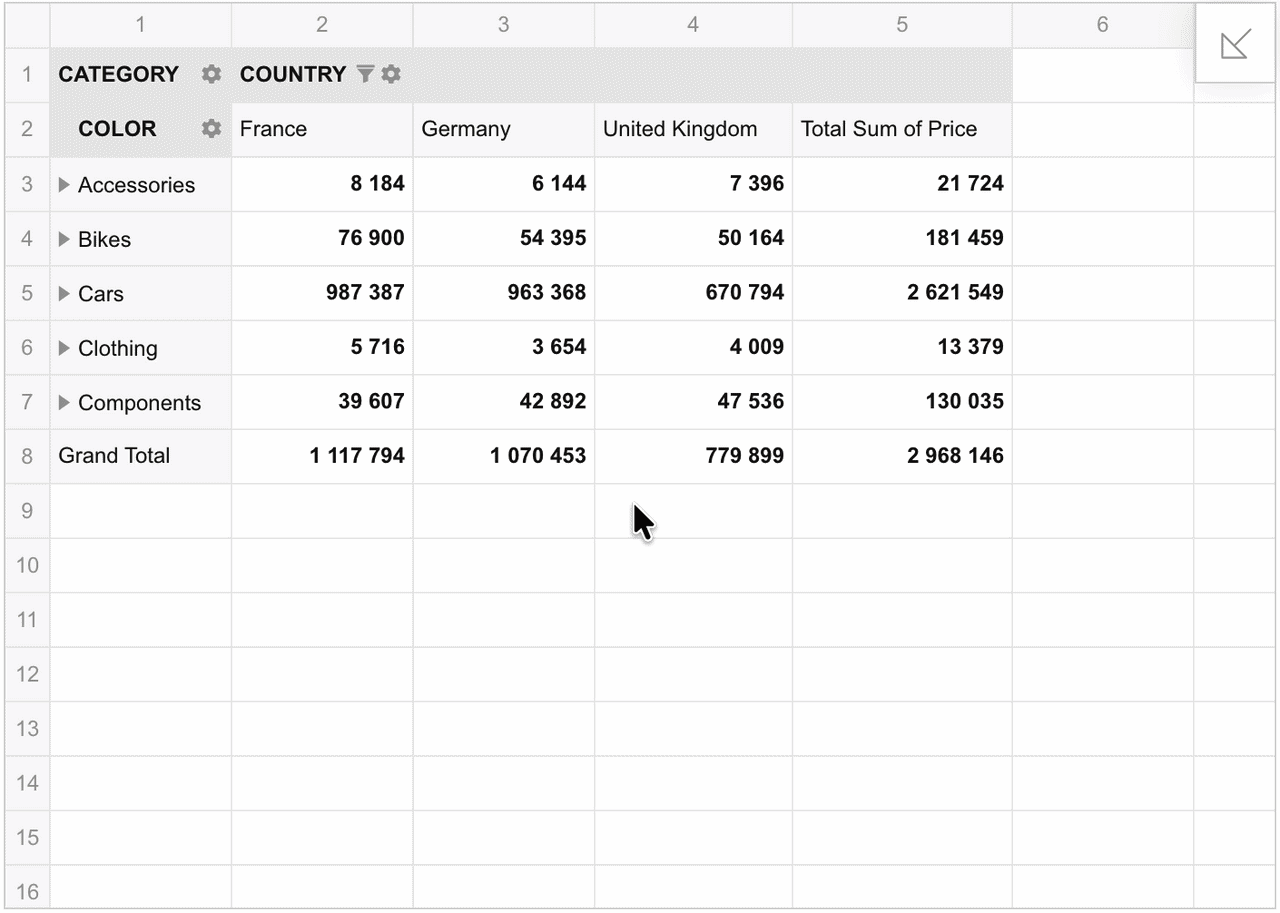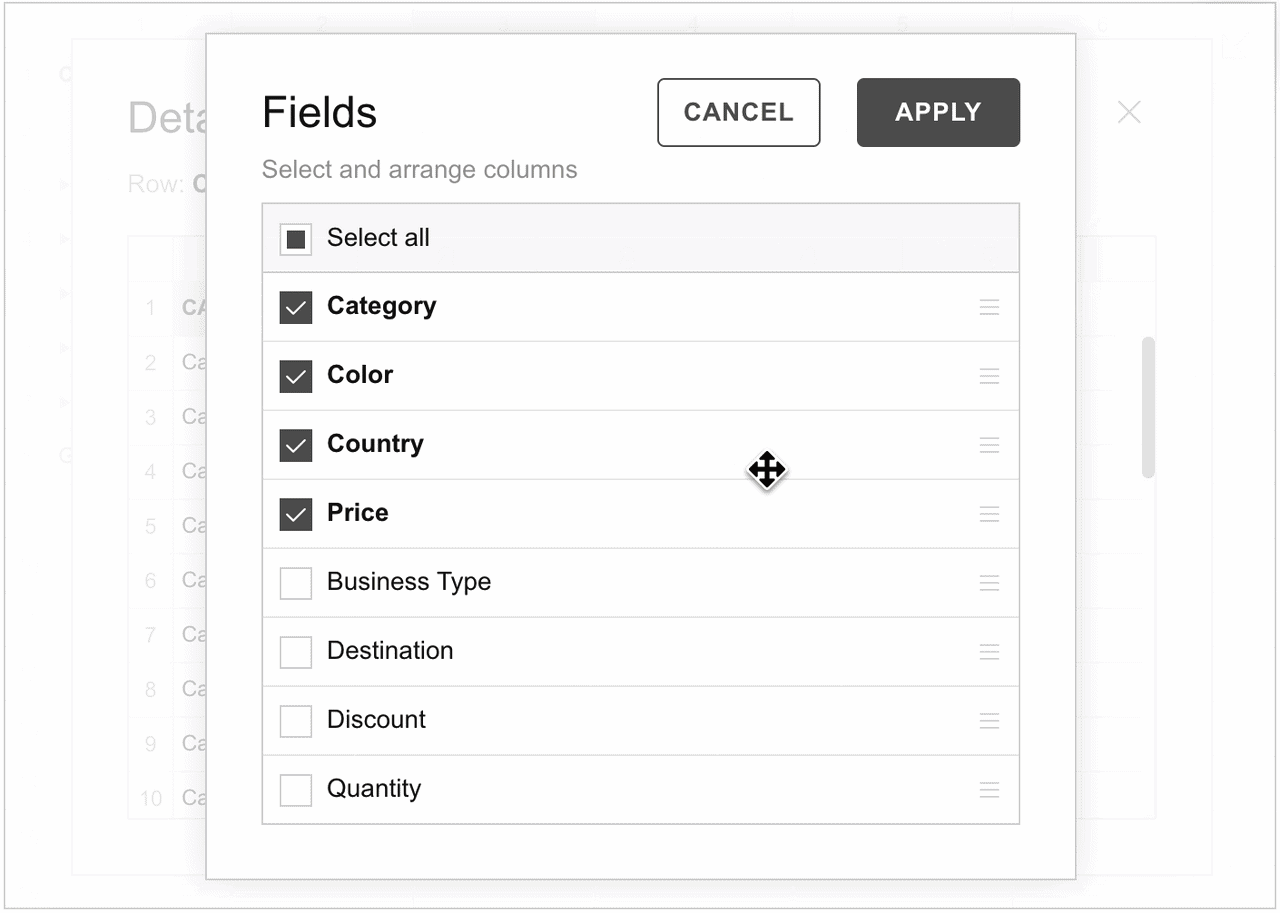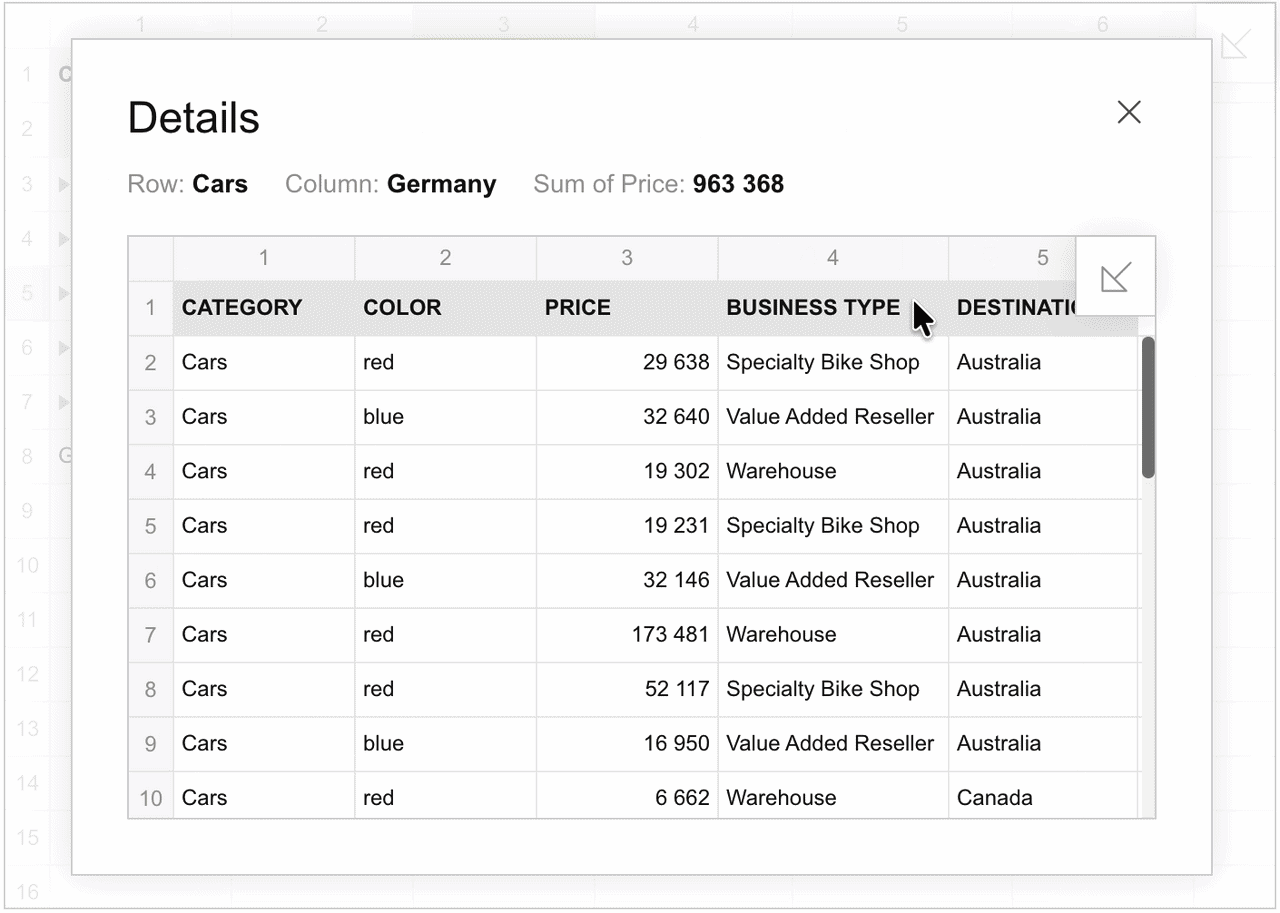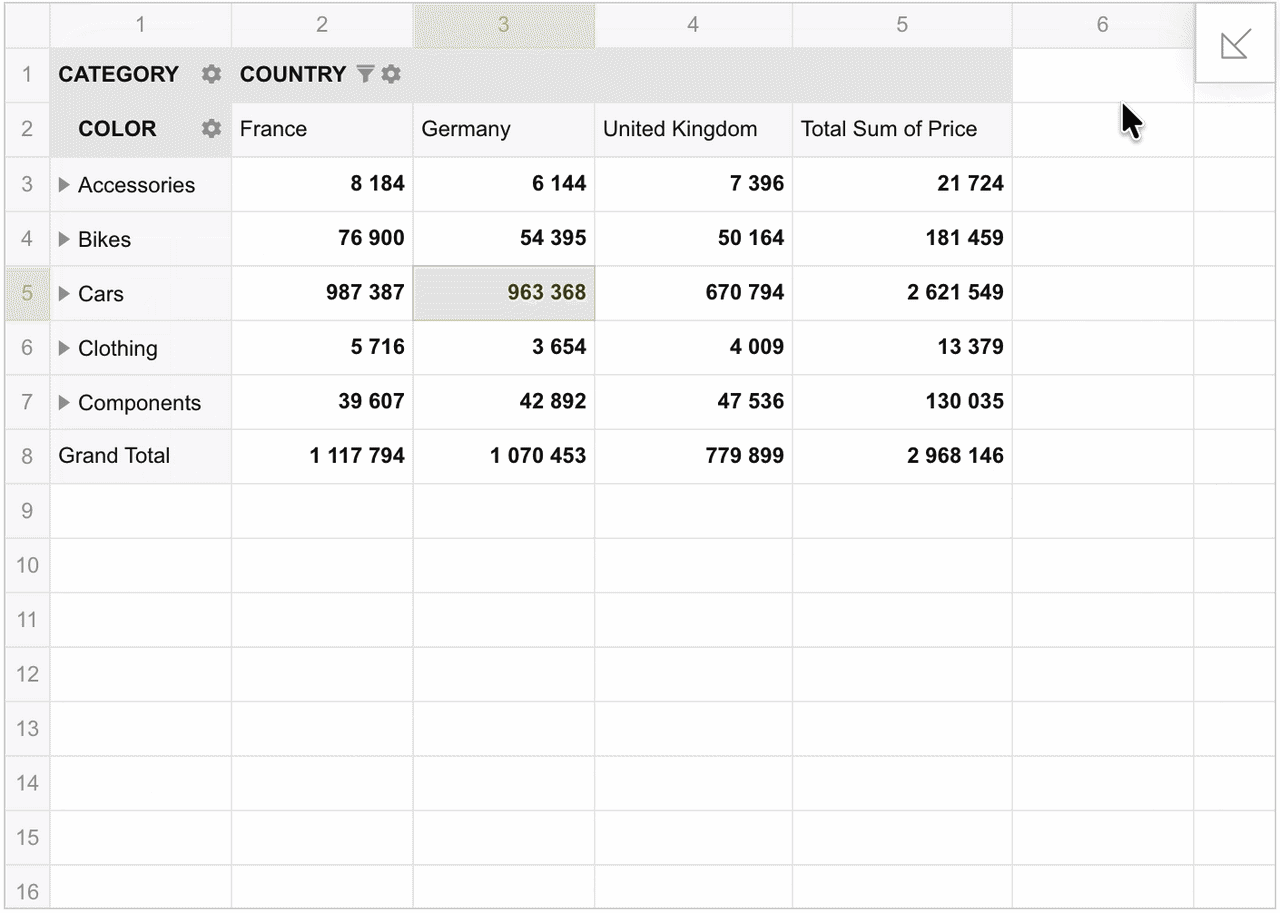
Step 1. Double-click a value cell or use the Drill through option from the context menu. As a result, a pop-up window listing the records that compose the value appears.
Step 2. Open the Field List.
Step 3. Add or remove fields from the drill-through view.
Note that the slice for the main view will remain the same.