
Mondrian vs Elasticsearch: What to Choose For Your Project
Finding an analytics back-end engine for your business application is a challenge for developers and data warehouse architects.
Your choice always depends on a wide range of business, application-specific and hardware requirements which need to be considered in the early phases of the software development lifecycle.
To help you make the right choice about the solution that fits the far-reaching goals of your project, we’ve decided to bring to the spotlight two powerful (yet different by nature) tools - Elasticsearch and Mondrian, cover in brief their high-level features and investigate the core purposes of a search engine and an OLAP server.
Elasticsearch
The largest companies in the world give their preferences to Elasticsearch. It’s no surprise - Elasticsearch embodies the best features of a document-oriented data storage, multi-tenant search, and analytical engine at the same time. Being optimized for search and retrieval, it powers applications with state-of-art search features. Its multi-tenancy gives you the ability to have as many indexes on a cluster as you need.
Beyond its searching capabilities, it also supports analytics and offers effective aggregation that helps extract value from your data.
What is under the hood?
At the heart of Elasticsearch is Apache Lucene - one of the most beloved information retrieval libraries, which is known for its performance, scalability, and relevancy.
Near real-time
Elasticsearch is called a near real-time search platform because it uses a lightweight process of making new documents searchable by refreshing every shard once every second.
Deployment
As a rule, adding Elasticsearch to your architecture design is a painless process - you can run it either on-premises or in the cloud. Implementation takes minimum efforts but gives maximum results in the long run.
Performance & scalability
Scalability is always a make-or-break issue but Elasticsearch has a distributed nature that ensures the overall search performance. It easily scales out due to dividing each index into multiple shards. Sharding allows you to parallelize operations between shards and replicating of your index’s shards ensures availability in case of the failure of one or more nodes. Moreover, you can control the number of replicas dynamically, after the index is created, but the number of shards needs to be defined at the time of the index creation.
Flexibility
One of the core specialties of Elasticsearch is that there is no need to specify the schema up front. Elasticsearch takes upon itself indexing of the documents and automatically infers its types and fields. That way it helps you get straight to exploring your data as quickly as possible.
Security
You are able to implement various security measures to your cluster with the help of X-Pack - an extension of the Elastic Stack (which also provides with alerting, monitoring, reporting, machine learning features).
Usually, such measures include preventing private data revelation and execution of expensive requests or external code through dynamic scripts. Also, you may want to impose restrictions on updating rights.
API
All the features of Elasticsearch are exposed via the RESTful interface.
Furthermore, you can interact with Elasticsearch in any language of your choice. Support for languages is wide - Java, Python, Curl, PHP, SQL, JavaScript, Ruby, and others.
Community
Being an open-source product, Elasticsearch is backed by developers from all around the world.
Try visiting Elastic Forum - it will give you an incomparable sense of belonging to the international community.
Documentation, releases & updates
The first thing that catches one’s eye is how Elasticsearch documentation is well-organized and up-to-date.
Another thing you may like is the section with use cases which helps discover how various organizations tackle searching and analytics challenges with the help of Elasticsearch and other products of the ELK stack.
The minor releases and fixes happen frequently. Major releases are frequent as well - once every two or four months.
Is it free?
Yes, it’s a free search engine that is released as open source under the Apache 2.0 License.
What we think
Elasticsearch is about speed and flexibility. If you need to manage complex data flows, it’s the best choice. It makes the searching process painless and effective.
You can use Elasticsearch both as a primary store and search engine. But the best practice is to use Elasticsearch in addition to the existing database.
And to empower your application with a business intelligence tool, you can try Flexmonster - it helps transform the data from your index into insights with powerful filtering, aggregating, and sorting features.
To learn in practice how to build a report based on the data from an Elasticsearch index, please refer to the Connecting to Elasticsearch article.
Now let’s get to the Mondrian overview.
Mondrian
Mondrian is an open source OLAP engine that was released in 2002. Its creation was inspired mainly by SSAS and a desire to overcome the problem of time-consuming report creating process.
How does it work?
The Pentaho architects combined the best features of ROLAP (relational online analytical processing), its simplified structure and performance of MOLAP (multidimensional online analytical processing).
Technically, it serves as an intermediary between a data warehouse and analysis tools. With the help of logical descriptions of the data and JDBC, it fetches the data from a database, converts MDX queries to SQL queries and sends OLAP cubes as a response to the reporting tool. Mondrian’s principal feature is that it cashes cubes in memory to be able to respond to queries fast.
Also, it’s important to understand the constructs of the Mondrian schema. A cube is a collection of dimensions and measures. Dimensions present the attributes by which measures should be divided into categories. These dimensions and hierarchies are mapped onto tables from your database via the schema.
Near real-time
You can achieve a near real-time experience with Mondrian because ROLAP engines don’t calculate intersections of dimensions beforehand, meaning the data is available to end-users as soon as it’s updated in the database.
That is what makes Mondrian a good choice for real-time systems - you can run multi-dimensional queries on a constantly changing database. For this, you can use its cache control API.
Deployment
You can run Mondrian in a web container (Tomcat or JBoss) or embed as a part of your application.
Performance & scalability
Mondrian uses in-memory storage of calculations to increase speed. Despite the efficiency of Mondrian itself, it can slow down your application if your SQL queries are not optimized or schema is poorly designed. Besides, setting up, maintaining and restructuring OLAP cubes may cost you a lot in terms of developer’s time which is often more expensive resource than power and memory. Still, by using the right configurations, you can scale Mondrian for use by hundreds or thousands of users.
Flexibility
It’s flexible in the sense that it can be embedded in a diversity of environments and integrated with the third-party tools. But Mondrian schema language imposes certain limitations which can be overcome by adding custom plug-ins to the application.
Security
To limit access to the certain portions of the OLAP cube, you can define user roles in the schema definition by using role mapping of the BA server.
API
Mondrian doesn’t provide with REST API but you can use third-party REST APIs wrapped around the Mondrian library.
Community
Mondrian is also an open-source project anyone can contribute to. The official Pentaho forum is at your service in case you need to ask a question related to the functionality of Mondrian. However, it doesn’t seem to be actively used.
Documentation, releases & updates
Documentation is comprehensive but not skimmable enough. Unfortunately, it gives the impression of a single long document which you scroll down until finding necessary information.
The latest official stable version 3.0 was released in 2008. Since then, Mondrian is supported and updated mostly by the developers.
Is it free?
Yes, Mondrian is free and open-source. It’s licensed under the ETL.
What we think
All in all, Mondrian is a good option if you have a single relational database as a storage layer that doesn’t completely meet the needs for fast fetching search results via queries. It extends the relational database functionality by providing a dimensional view of data, caching and higher level calculations.
If you decided to use it, you definitely need an advanced front-end tool for displaying and analyzing the data from cubes. That is for what Flexmonster is designed. You can connect to Mondrian via XMLA or Flexmonster Accelerator (a special server-side utility for fast data transfer) and start exploring the OLAP data. To find out more details, please refer to the Connecting to Pentaho Mondrian article.
Bringing it all together
Both Mondrian and Elasticsearch can be used for effective querying the pre-aggregated data and analyzing it in near real-time though they use essentially different technologies. However, it seems that the former eventually became an outdated and less popular solution due to the competition of open source tools in the IT market. Moreover, writing the Mondrian schemas requires a higher learning curve and can be a tedious process.
Elasticsearch is more received by the developer community (especially by DevOps engineers) and it outreaches Mondrian in diverse aspects: a wider range of supported data types, scalability, ability to communicate via the REST interface and strong community support. Besides, it’s great for logs analysis. Other key features are near real-time search and schema-less architecture. We recommend getting hands-on experience to make sure that Elasticsearch is designed for easy data integration and with excellent performance in mind.
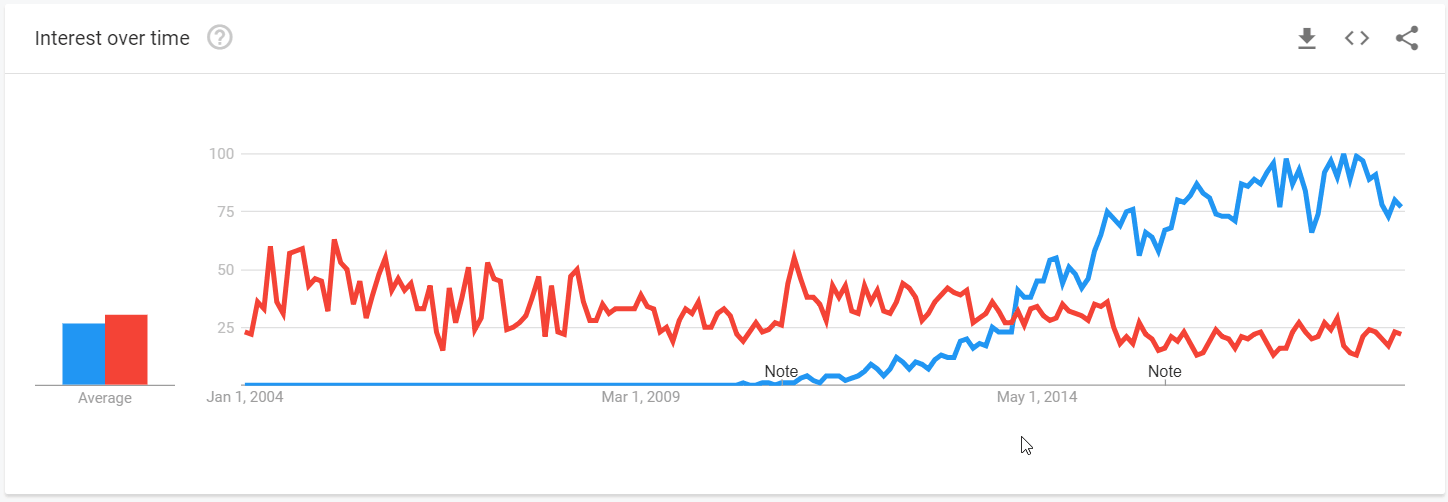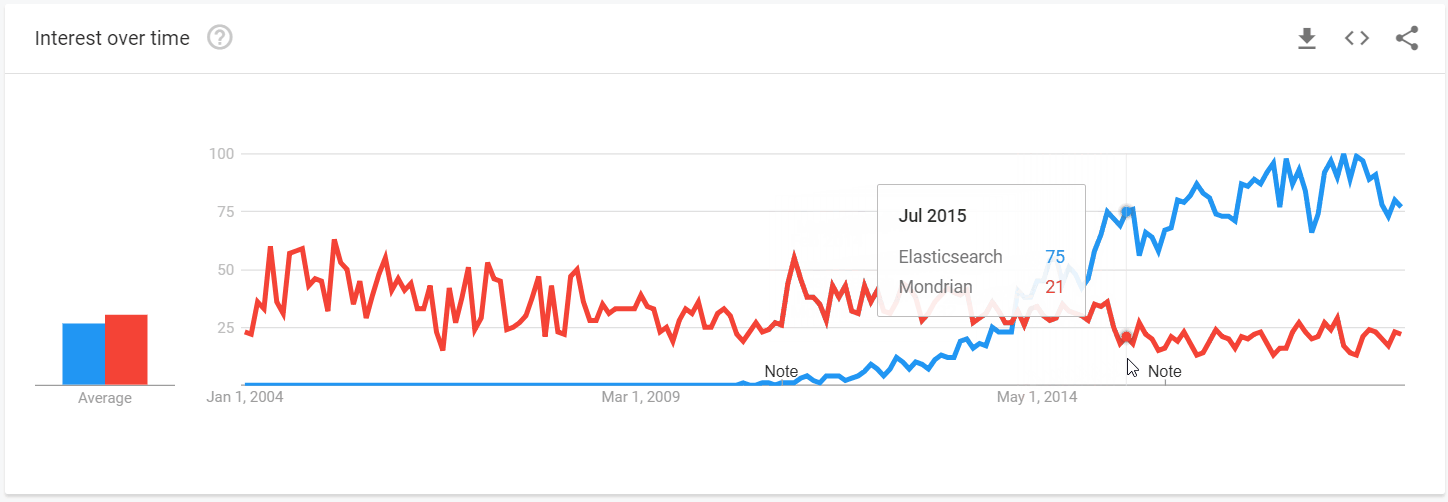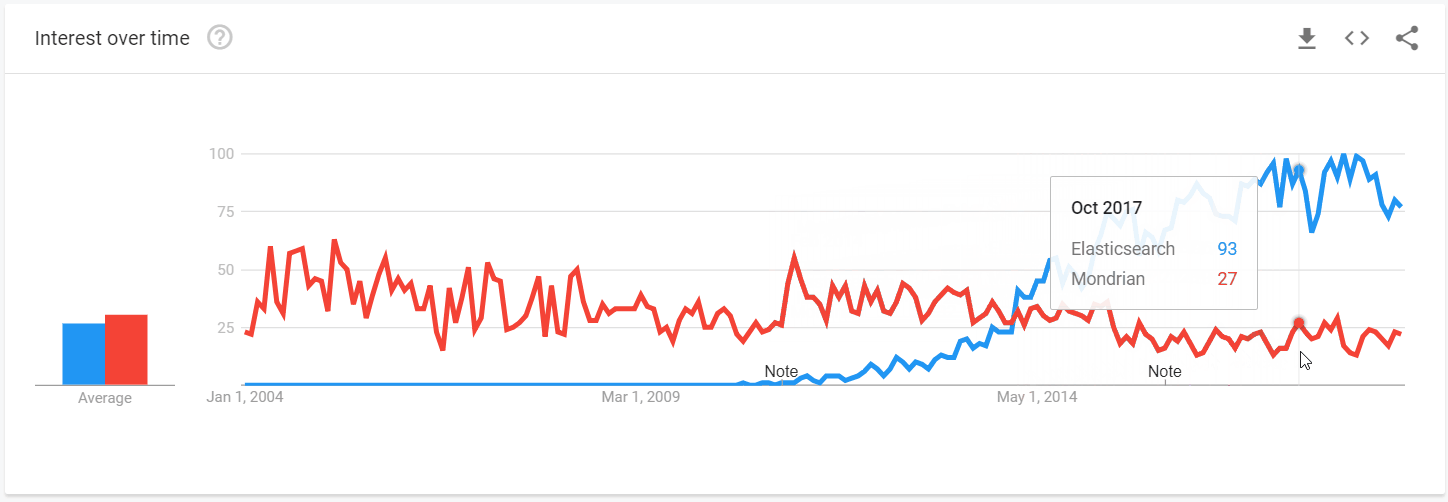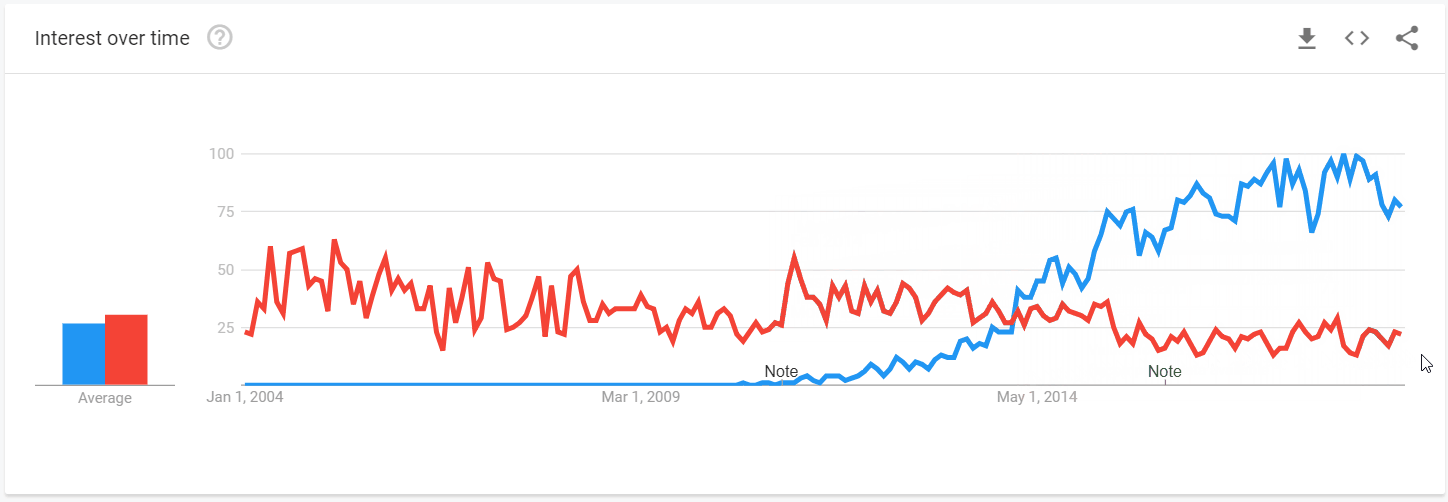
Comparing popularity
Our conclusions of Elasticsearch and Mondrian popularity are based on the analysis of search queries via Google Trends. It showed how the interest in both solutions changed over the past decade. On the trendline graph, you can notice that Mondrian was in demand during the first 10 years after its release, but its decrease in popularity in 2014 coincided with the increase of Elasticsearch popularity which followed soon after its major updates.
Final thoughts
We hope now you are ready to make a well-informed decision about the analytics back-end engine for your project.
Whichever solution you pick, you can always rely on Flexmonster. It serves as a business intelligence tool for your data and opens up a wide range of opportunities - you can connect either to Elasticsearch or Mondrian, get the summarized data from an index or OLAP cube and start your speed-of-thought analysis. No matter how large your dataset is - Flexmonster can handle it.